
Before I describe my experience implementing GPU virtualization, I want to first describe the overall architecture. As the internal codename for Windows Vista was “Longhorn”, we referred to this architecture as LDDM (Longhorn Display Driver Model). Later it became officially known as WDDM (it even has its own Wikipedia page).
As I said in the previous post, CPUs can switch between applications very quickly because they are designed to do so.
The GPU hardware at that time had no virtual memory – all memory accesses were performed by the driver passing a physical address to the hardware. As the hardware only operated using physical addresses, the operating system had to physically page memory in and out of video memory. And as the hardware could not preempt a task while running midstream, the only way to ensure that we could switch applications in a timely manner was to ensure that the command buffers contained a payload that could finish within a reasonable amount of time.
We did work with graphics vendors so they could provide better preemptability, but a big selling point was that LDDM worked on the majority of existing GPU hardware.
We ended up breaking the graphics driver into two parts: a user mode driver and a kernel mode driver.
The user mode driver contains most of the intelligence:
- It generates the command buffers, including any additional behaviors like applying game hacks. Each command buffer targets a specific core.
- If work needs to be synchronized across cores, it uses a fencing mechanism to insert waits and completion events within the command buffers to ensure that the data execution is properly synchronized.
- The command buffers need to contain physical addresses, but the user mode driver should not generate these physical addresses for two reasons:
- The OS can move allocations around without the user mode driver knowing about it.
- There is a security concern where a bad actor could insert physical addresses that cause data to be accessed in unsecure ways.
- Instead, for each command buffer they submit, they also submit a patch list, which contains information about each allocation accessed within the command buffer and the offset of each reference within the command buffer.
- If the user mode driver were to crash, it crashes the program without impacting the rest of the system.
The kernel mode driver is generally much simpler:
- The driver reports all the GPU cores to the operating system, along with some basic information about each core.
- Our scheduler maintains a per application work queue for each core. When a task finished on a core, the scheduler would determine the next command buffer to run.
- Before running a new command buffer, the scheduler will:
- Check to see if all memory associated with the command buffer already exists in video memory. If not, it will page it into video memory (potentially causing other allocations to be evicted to make room).
- Call the driver to create a DMA buffer (that contains physical addresses and can actually run on the hardware) from the command buffer, patch list, and the physical addresses of each allocation.
- The scheduler will then pass the DMA buffer to the driver to run.
The overall architecture looked like this:
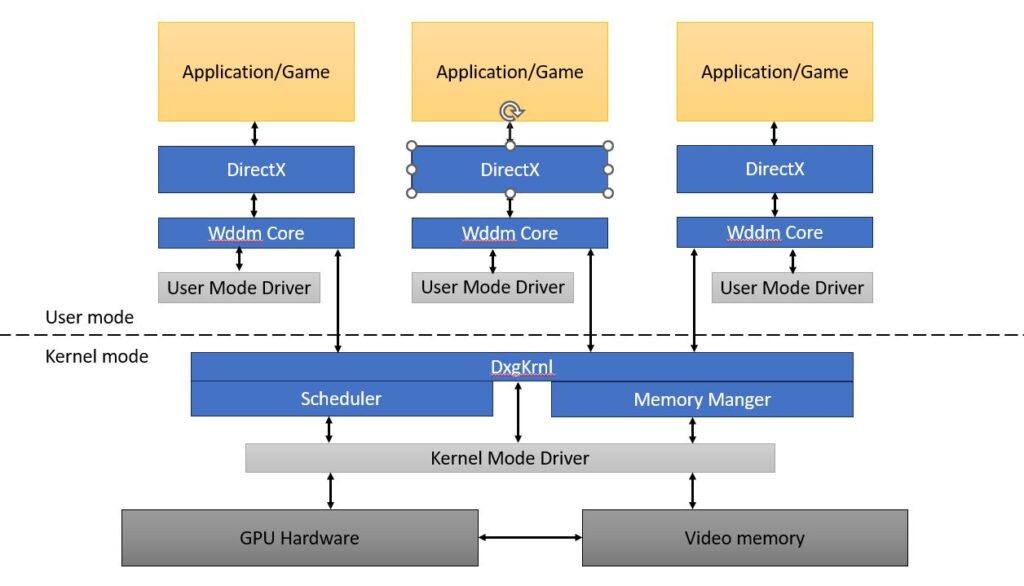
One side effect of the new architecture is that the operating system has much better visibility into which command buffers are in waiting in queues, which are being currently executed, and when everything gets displayed. This allowed us to create better tooling, and the most useful tool is called GPUView (one of the many reasons why Steve Pronovost is now a Distinguished Engineer!) A user can run a tool to capture a trace, email us the resulting file, and we can use GPUView to analyze what happened during the trace. This provided enough visibility to allow us to debug most performance issues.
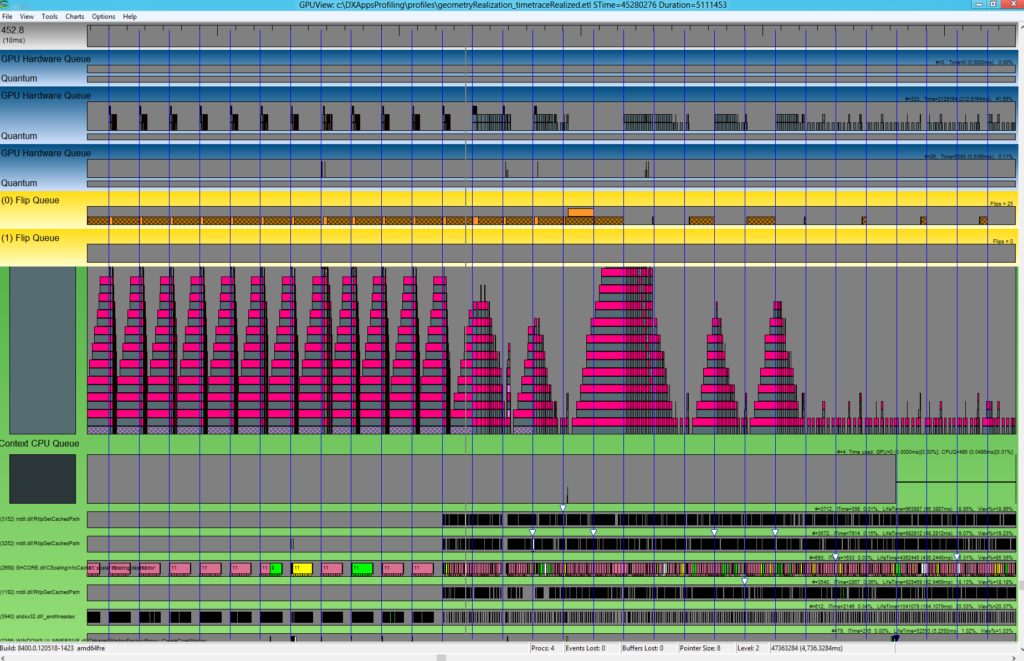
So on one hand, our new architecture requires additional steps (e.g. moving video memory around) that make certain things slower. But on the other hand, for the first time we now had the ability to debug real world scenarios ourselves rather than simply filing bugs against graphics vendors (which may or may not get fixed). This went a long ways toward reclaiming some of the performance lost to the inherent overhead of our system. In the end, I think that this capability alone justified the entire project.